What is the Linux Scheduler?
This article is Part 2 in a 3-Part Series.
- Part 1 - Linux Scheduler Series: Introduction
- Part 2 - What is the Linux Scheduler?
- Part 3 - Understanding sched_class
Introduction
In this post, I introduce the Linux scheduler, describe its job, and explain where it fits in with respect to the rest of the kernel. We won’t worry about the scheduler’s internals just yet. Instead, we’ll make several simplifying assumptions while focusing on understanding what the scheduler does at a high level.
What is the scheduler?
Linux is a multi-tasking system. At any instant, there are many processes active at once, but a single CPU can only perform work on behalf of one process at a time. At a high level, Linux context switches from process to process, letting the CPU perform work on behalf of each one in turn. This switching occurs quickly enough to create the illusion that all processes are running simultaneously. The scheduler is in charge of coordinating all of this switching.
Where Does the Scheduler Fit?
You can find most scheduler-related code under kernel/sched. Now, the
scheduler has a distinct and nontrivial job. The rest of the kernel doesn’t
know or care how the scheduler performs its magic, as long as it can be called
upon to schedule tasks. So, to hide the complexity of the scheduler, it is
invoked with a simple and well-defined API. The scheduler - from the
perspective of the rest of the kernel - has two main responsibilities:
- Responsibility I: Provide an interface to halt the currently running process and switch to a new one. To do so, the scheduler must pick the next process to run, which is a nontrivial problem.
- Responsibility II: Indicate to the rest of the OS when a new process should be run.
Responsibility I: Switching to the Next Process
To fulfill its first responsibility, the scheduler must somehow keep track of all the running processes.
The Runqueue
Here’s the first over-simplification: you can think of the scheduler as a system that maintains a simple queue of processes in the form of a linked list. The process at the head of the queue is allowed to run for some “time slice” - say, 10 milliseconds. After this time slice expires, the process is moved to the back of the queue, and the next process gets to run on the CPU for the same time slice. When a running process is forcibly stopped and taken off the CPU in this way, we say that it has been preempted. The linked list of processes waiting to have a go on the CPU is called the runqueue. Each CPU has its own runqueue, and a given process may appear on only one CPU’s runqueue at a time. Processes CAN migrate between various CPUs’ runqueues, but we’ll save this discussion for later.
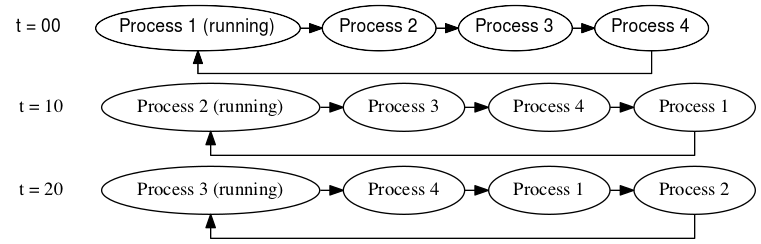
The scheduler is not really this simple; the runqueue is defined in the kernel
as struct rq, and you can take a peek at it’s definition
here. Spoiler
alert: it’s not a linked list! To be fair, the explanation that I gave above
more or less describes the very first Linux runqueue. But over the years, the
scheduler evolved to incorporate multiple scheduling algorithms. These include:
- Completely Fair Scheduler (CFS)
- Real-Time Scheduler
- Deadline Scheduler
The modern-day runqueue is no longer a linked list but actually a collection of
algorithm-specific runqueues corresponding to the list above. Indeed,
struct rq has the following members:
struct cfs_rq cfs; // CFS scheduler runqueue
struct rt_rq rt; // Real-time scheduler runqueue
struct dl_rq dl; // Deadline scheduler runqueueKeep these details at the back of your mind so that you don’t get bogged down. Remember: the goal here is to understand how the scheduler interoperates with the rest of the kernel. The main takeaway is that a process is allowed to run for some time, and when that time expires, it gets preempted so that the next process can run.
Preemption vs Yielding
Preemption is not always the reason a process is taken off the CPU. For example, a process might voluntarily go to sleep, waiting for an IO event or lock. To do this, the process puts itself on a “wait queue” and takes itself off the runqueue. In this case, the process has yielded the CPU. In summary:
- “preemption” is when a process is forcibly kicked off the CPU
- “yielding” is when a process voluntarily gives up the CPU.
schedule()
With a conceptual understanding of the runqueue, we now have the background to
understand how Responsibility I is carried out by the scheduler. The schedule
function is the crux of Responsibility I: it halts the currently running
process and runs the next one on the CPU. This function is referred to by many
texts as “the entrypoint into the scheduler”. schedule invokes __schedule
to do most of the real work. Here is the portion relevant to us:
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
/* CODE OMMITTED */
next = pick_next_task(rq, prev, cookie);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
rq->clock_skip_update = 0;
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
trace_sched_switch(preempt, prev, next);
rq = context_switch(rq, prev, next, cookie);
}
}The function pick_next_task looks at the runqueue rq and returns the
task_struct associated with the process that should be run next. If we
consider t=10 in Figure 1, pick_next_task would return the task_struct for
Process 2. Then, context_switch switches the CPU’s state to that of the returned
task_struct. This fullfills Responsibility I.
Responsibility II: When Should the Next Process Run?
Great, so we’ve seen that schedule() is used to context switch to the next
task. But when does this actually happen?
As mentioned previously, a user-space program might voluntarily go to sleep
waiting for an IO event or a lock. In this case, the kernel will call
schedule on behalf of the process that needs to sleep. But what if the
user-space program never sleeps? Here’s one such program:
int main()
{
while(1);
}If schedule were only called when a user-space program voluntarily sleeps,
then programs like the one above would use up the processor indefinitely. Thus, we
need a mechanism to preempt processes that have exhausted their time slice!
This preemption is accomplished via the timer interrupt. The timer
interrupt fires periodically, allowing control to jump to the timer interrupt
handler in the kernel. This handler calls the function update_process_times,
shown below.
/*
* Called from the timer interrupt handler to charge one tick to the current
* process. user_tick is 1 if the tick is user time, 0 for system.
*/
void update_process_times(int user_tick)
{
struct task_struct *p = current;
/* Note: this timer irq context must be accounted for as well. */
account_process_tick(p, user_tick);
run_local_timers();
rcu_check_callbacks(user_tick);
#ifdef CONFIG_IRQ_WORK
if (in_irq())
irq_work_tick();
#endif
scheduler_tick();
run_posix_cpu_timers(p);
}Notice how update_process_times invokes scheduler_tick. In
scheduler_tick, the scheduler checks to see if the running process’s time has
expired. If so, it sets a (over-simplification alert) per-cpu flag called
need_resched. This indicates to the rest of the kernel that schedule
should be called. In our simplified example, scheduler_tick would set this flag
when the current process has been running for 10 milliseconds or more.
But wait, why the heck can’t scheduler_tick just call schedule by
itself, from within the timer interrupt? After all, if the scheduler knows that
a process’s time has expired, shouldn’t it just context switch right away?
As it turns out, it is not always safe to call schedule. In particular, if
the currently running process is holding a spin lock in the kernel, it cannot
be put to sleep from the interrupt handler. (Let me repeat that one more time
because people always forget: you cannot sleep with a spin lock. Sleeping
with a spin lock may cause the kernel to deadlock, and will bring you anguish
for many hours when you can’t figure out why your system has hung.)
When the scheduler sets the need_resched flag, it’s really saying, “please
dearest kernel, invoke schedule at your earliest convenience.” The kernel
keeps a count of how many spin locks the currently running process has
acquired. When that count goes down to 0, the kernel knows that it’s okay to
put the process to sleep. The kernel checks the need_resched flag in two main
places:
- when returning from an interrupt handler
- when returning to user-space from a system call
If need_resched is True and the spinlock count is 0, then the kernel calls
schedule. With our simple linked-list runqueue, this delayed invocation of
schedule implies that a process can possibly run for a bit longer than its
timeslice. We’re cool with that because it’s always safe to call schedule
when the kernel is about to return to user-space. That’s because user-space
programs are allowed to sleep. So, by the time the kernel is about to return
to user-space, it cannot be holding any spinlocks. This means that there won’t be
a large delay between when need_resched is set, and when schedule gets called.
Conclusion
This concludes our exploration of how the kernel interfaces with the scheduler. Read on as we delve deeper into the scheduler’s implementation!